[상황]
문득,
API을 개발하다가 DB 데이터 존재 유무를 확인할 때 Count, Limit, Exists에서 Count가 비효율적이라는 것은 알고 있지만,
실질적으로 얼마나 차이나는지는 확인해보지 못하였습니다.

'쇠뿔도 단김에 빼라'
궁금한 내용에 대해서 뒤로 미루지 말고 직접 테스트를 진행해보았습니다.

테스트 환경 : MariaDB
[탐색을 도와줄 DB Dump Table]
create table DUMP
(
id varchar(36) default uuid() not null primary key,
name varchar(255) null,
level varchar(255) null
);
[Dump Table Data Count]
성능을 비교하기 위해서, Dump Table에 데이터를 20,000,000개를 저장해놓았습니다.
SELECT COUNT(*) FROM DUMP;

이제부터, Count, Exist, Limit에 대해서 조회를 진행해보자
[Index O]
SELECT COUNT(*) FROM DUMP WHERE name like '%name : 1%' → 7028ms
SELECT EXISTS(SELECT 1 FROM DUMP WHERE name like '%name : 1%') → 120ms
SELECT 1 FROM DUMP WHERE name like '%name : 1%' limit 1 → 122ms
[Index X]
SELECT COUNT(*) FROM DUMP WHERE name like '%name : 1%' → 15788ms
SELECT EXISTS(SELECT 1 FROM DUMP WHERE name like '%name : 1%') → 166ms
SELECT 1 FROM DUMP WHERE name like '%name : 1%' limit 1 → 115ms
시간적 성능으로 살펴보았을 때, Limit, Exists에 비해 Count가 걸리는 시간이 큰 차이를 나타내고 있는 것을 확인하고 있습니다.
MariaDB의 Profile Info으로도 확인해보자
MySQL - 쿼리 성능(실행 시간, CPU 사용량 등) 확인하는 방법 [Profiling]
MySQL Profiling MySQL에서 실행한 쿼리들이 각 수행 시간이 얼마가 걸렸는지 확인할 수 있는 기능으로 쿼리 프로파일링(Query Profiling)을 제공합니다. profiling 설정을 활성화하면 앞으로 실행되는 모든
jaehoney.tistory.com
SELECT @@profiling; # 현재 Profile 설정 확인 (0 : 사용 안함, 1 : 사용)
SET profiling=1; # profile 사용 설정
SHOW profiles; # 실행했던 Query 수행 시간 조회
SHOW profile FOR QUERY 2; # 실행했던 Query 정보 자세히 보기
SHOW profile CPU FOR QUERY 2; # CPU 사용 정보까지 자세히 보기
SELECT COUNT(*) FROM DUMP WHERE name like '%name : 1%'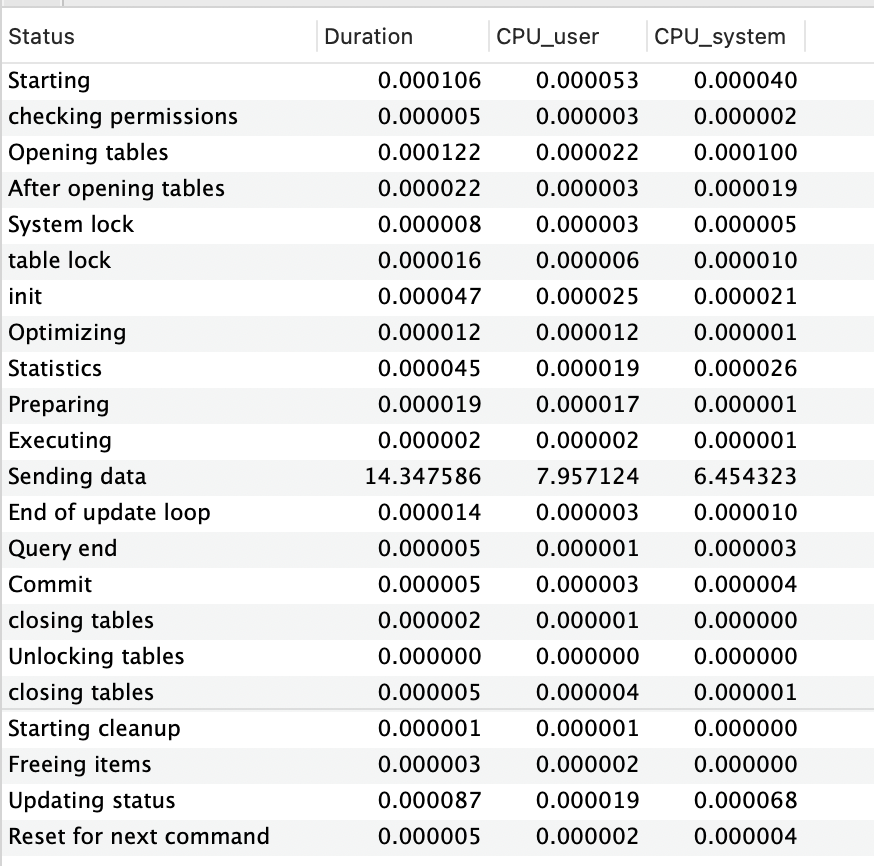
SELECT EXISTS(SELECT 1 FROM DUMP WHERE name like '%name : 1%')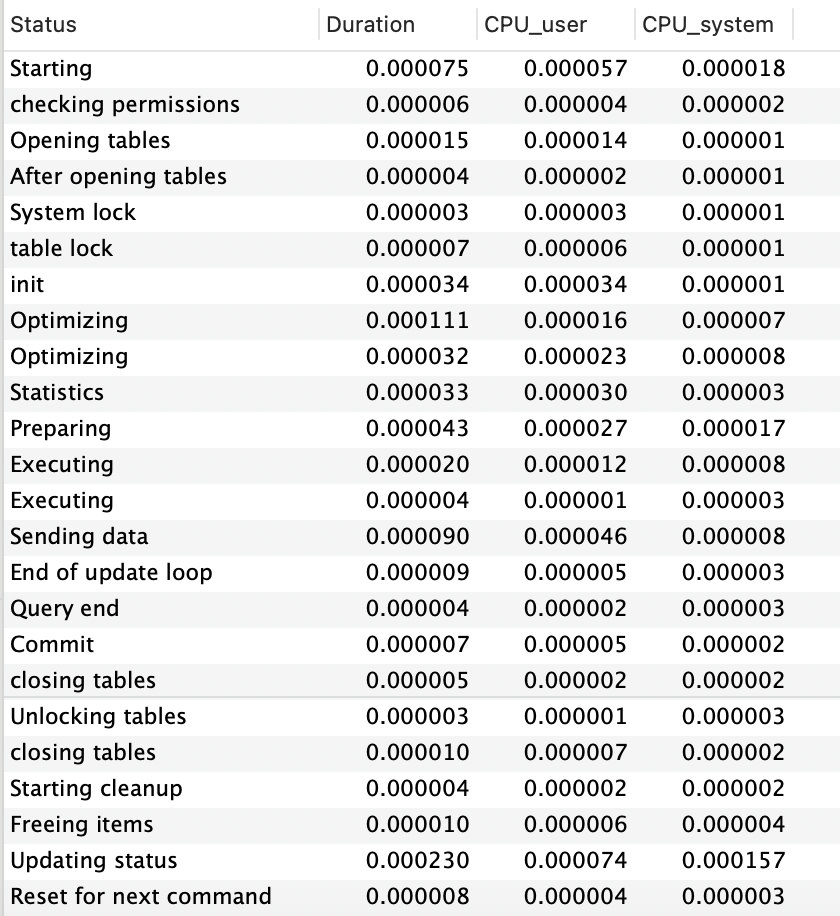
SELECT 1 FROM DUMP WHERE name like '%name : 1%' limit 1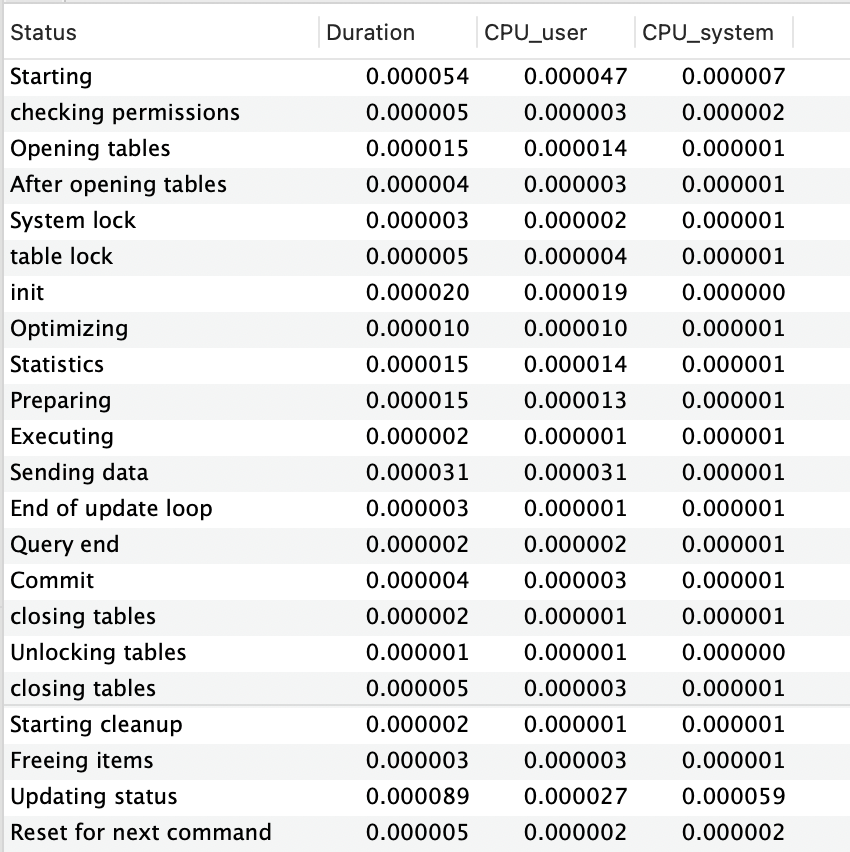
동일하게, Limit, Exists에 비해 Count가 걸리는 시간이 큰 차이를 나타내고 있는 것을 확인하고 있습니다.
또한, Exists는 Limit와 다르게 [Executing, Optimizing]가 2번씩 진행되는 것을 확인할 수 있습니다.
→ 해당 현상이 나오는 것에 대해 제가 분석한 내용으로는 Exists는 Sub Query로 진행되기 때문입니다.

그러면, Spring에서 우리가 사용하는 JPA, QueryDsl, R2DBC에서는 어떻게 존재 여부를 확인하고 있는지 알아봅시다.
[QueryDsl]
1. 과거 버전 ~ 2.6.X
@Override
public boolean exists(Predicate predicate) {
return createQuery(predicate).fetchCount() > 0;
}
이전 버전을 사용하시는 분들이 작성한 QueryDsl exists 성능 개선 관련된 글들을 많이 찾아보실 수 있습니다.
그 이유가 바로 QueryDsl 예전 버전에서는 존재 유무 확인을 Count 진행하였기 때문에 성능적 이슈가 있었던 것입니다.
그래서, 대부분 성능 이슈를 해결하기 위해서 exists을 사용하지 않고, QueryDsl 문법 마지막에 fetchFirst()을 사용해서 Limit(1)으로 존재 유무를 확인하는 것으로 개선했다는 내용을 많이 찾아보실 수 있습니다.
이렇듯, Count로 존재 유무를 확인하는 로직에 대해서 이전부터 성능 개선을 위해서 Limit(1)으로 개선하는 일이 있었다는 것을 알 수 있습니다.
2. 2.7.0 ~ 현재 버전
@Override
public boolean exists(Predicate predicate) {
return createQuery(predicate).select(Expressions.ONE).fetchFirst() != null;
}
Count 성능 이슈로 인하여 2.7.0버전부터는 fetchFirst()을 사용해서 Limit(1) 방식으로 데이터의 존재 여부를 확인하는 것을 보실 수 있습니다.
[R2DBC Repository]
Mono<Boolean> doExists(Query query, Class<?> entityClass, SqlIdentifier tableName) {
RelationalPersistentEntity<?> entity = this.getRequiredEntity(entityClass);
StatementMapper statementMapper = this.dataAccessStrategy.getStatementMapper().forType(entityClass);
-------------------
StatementMapper.SelectSpec selectSpec = statementMapper.createSelect(tableName).limit(1);
-------------------
if (entity.hasIdProperty()) {
selectSpec = selectSpec.withProjection(new SqlIdentifier[]{((RelationalPersistentProperty)entity.getRequiredIdProperty()).getColumnName()});
} else {
selectSpec = selectSpec.withProjection(new Expression[]{Expressions.just("1")});
}
Optional<CriteriaDefinition> criteria = query.getCriteria();
if (criteria.isPresent()) {
Objects.requireNonNull(selectSpec);
selectSpec = (StatementMapper.SelectSpec)criteria.map(selectSpec::withCriteria).orElse(selectSpec);
}
------------------------
PreparedOperation<?> operation = statementMapper.getMappedObject(selectSpec);
return this.databaseClient.sql(operation).map((r, md) -> {
return r;
}).first().hasElement();
------------------------
}
R2DBC에서도 exists을 확인하는 로직은 Limit(1)을 통해서 진행되고 있는 것을 확인하실 수 있습니다.
[JpaRepository]
public <S extends T> boolean exists(Example<S> example) {
Specification<S> spec = new ExampleSpecification(example, this.escapeCharacter);
CriteriaQuery<Integer> cq = this.entityManager.getCriteriaBuilder().createQuery(Integer.class).select(this.entityManager.getCriteriaBuilder().literal(1));
this.applySpecificationToCriteria(spec, example.getProbeType(), cq);
TypedQuery<Integer> query = this.applyRepositoryMethodMetadata(this.entityManager.createQuery(cq));
return query.setMaxResults(1).getResultList().size() == 1;
}
JPA에서도 exists을 확인하는 로직은 Limit(1)을 통해서 진행되고 있는 것을 확인하실 수 있습니다.
또한, Query가 복잡해져서 Repository에서 Method 이름을 통해 JPQL Query을 만드는 것이 힘들어졌을 때
Limit 1을 사용해도 되지만, Exists로도 접근할 수 있지만, Limit 1을 사용하는 것이 더 효율적으로 보입니다.
→ @Query(Select Exists()…)을 JPQL은 지원하지 않습니다.
→ 하지만, Where 절에 Exists는 지원한다고 합니다.
Ex.
@Query(SELECT EXISTS(SELECT id, name, level FROM DUMP WHERE name LIKE '%name : 1%')) : X
-------------------------------------------------------------------------------
@Query(SELECT id, name, level FROM DUMP WHERE EXISTS(SELECT id FROM DUMP WHERE name LIKE '%name : 1%')) : OLIMIT와 EXISTS
주의!
해당 부분에 대해서 정보를 찾아보았으나, 객관적인 증거가 있는 자료는 찾지 못하였습니다.
검색하면서 찾아본 내용을 정리한 내용입니다.
EXISTS와 LIMIT 1는 모두 데이터의 존재를 확인하기 위한 비슷한 목표를 가지고 있지만, 내부적으로 동작하는 방식에는 차이가 있습니다.
EXISTS() : 서브쿼리가 반환하는 결과 집합이 존재하는지 여부를 확인하는 데 사용됩니다.
→ Sub Query가 하나 이상의 행을 반환하면 EXISTS()는 TRUE를 반환하고, 그렇지 않으면 FALSE를 반환합니다.
→ EXISTS()는 결과 집합의 첫 번째 행을 찾은 즉시 검색을 중단합니다.
LIMIT 1 : 결과 집합에서 첫 번째 행만 반환하도록 쿼리를 제한합니다.
→ 데이터베이스 엔진이 모든 결과를 스캔하지 않고 쿼리를 빠르게 반환하도록 돕습니다.
EXISTS()와 LIMIT 1이 비슷한 성능을 보이는 경우가 많습니다.
→ 쿼리 옵티마이저 최적화 기능 때문입니다.
→ EXISTS()와 LIMIT 1 쿼리를 실행할 때, 가능한 한 빠르게 첫 번째 일치하는 행을 찾은 다음 쿼리를 중단합니다.
LIMIT 1, EXISTS() 모두 첫 번째 일치하는 행을 찾는 데 걸리는 시간이 비슷하게 나타날 수 있기 때문입니다.
그러나, 항상 그런 것은 아닙니다.
특정 경우에는 EXISTS()가 LIMIT 1보다 빠르게 결과를 반환할 수 있습니다.
예를 들어, 정렬이 포함될 때
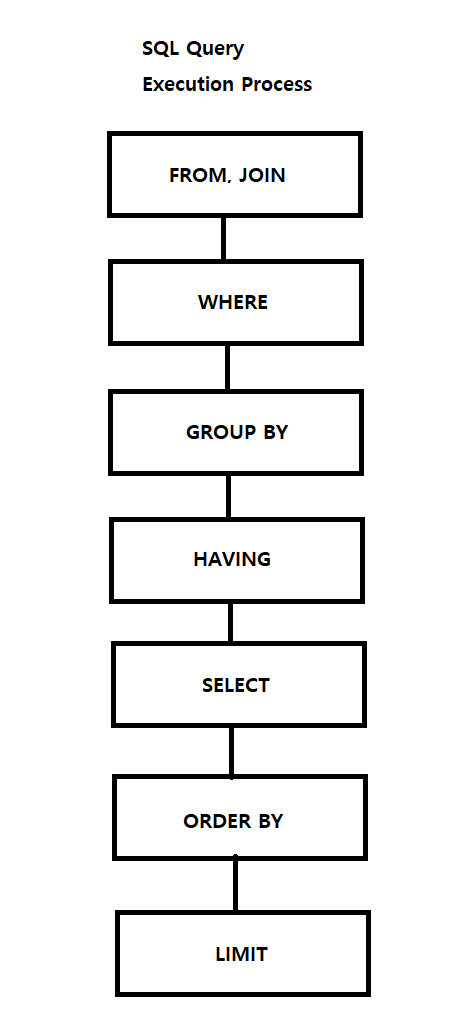
Query 처리 순서를 보면, LIMIT보다 ORDER BY의 우선순위가 높으며 LIMIT 1을 진행하기 앞서 모든 결과 집합이 정렬되어 있어야 합니다.
EXISTS()는 일치하는 행을 찾는 즉시 검색을 중단하지만, LIMIT 1은 결과 집합의 모든 행을 정렬을 기다려야 합니다.
이 경우 EXISTS()가 더 빠른 성능을 보일 수 있습니다.
SELECT EXISTS(SELECT id, name, level FROM DUMP WHERE name like '%name : 1%' ORDER BY level) → 221ms
SELECT id, name, level FROM DUMP WHERE name like '%name : 1%' ORDER BY level limit 1 → 21319ms
하지만, 존재를 확인할 때에는 정렬이 필요한 상황은 거의 없기 때문에 EXISTS(), LIMIT 1의 성능은 거의 비슷합니다.
즉, EXISTS()와 LIMIT 1의 성능 차이는 사용하는 쿼리와 데이터베이스의 상황에 따라 다르며, 항상 한 방법이 다른 방법보다 빠르다고 단정할 수는 없습니다.
→ 여러 요인(데이터베이스 엔진의 구현, 데이터의 분포, 인덱스의 사용 여부, 쿼리의 복잡성 등)에 따라서 성능이 달라지기 때문입니다.
[결론]
데이터 존재 확인할 때
COUNT() : X
EXISTS(), LIMIT 1 : O
→ 각 상황에 따라 성능이 달라질 수 있으니, EXISTS(), LIMIT 1을 사용할 지에 대해서는 성능 테스트를 통해서 결정하셔야 합니다!!
'Mysql' 카테고리의 다른 글
| 프로그래머스 SQL 고득점 Kit (String, Date) DATETIME에서 DATE로 형 변환 (0) | 2021.11.10 |
|---|---|
| 프로그래머스 SQL 고득점 Kit (String, Date) 오랜 기간 보호한 동물(2) (0) | 2021.11.09 |
| 프로그래머스 SQL 고득점 Kit (String, Date) 중성화 여부 파악하기 (0) | 2021.11.09 |
| 프로그래머스 SQL 고득점 Kit (String, Date) 이름에 el이 들어가는 동물 찾기 (0) | 2021.11.09 |
| 프로그래머스 SQL 고득점 Kit (String, Date) 루시와 엘라 찾기 (0) | 2021.11.09 |




댓글